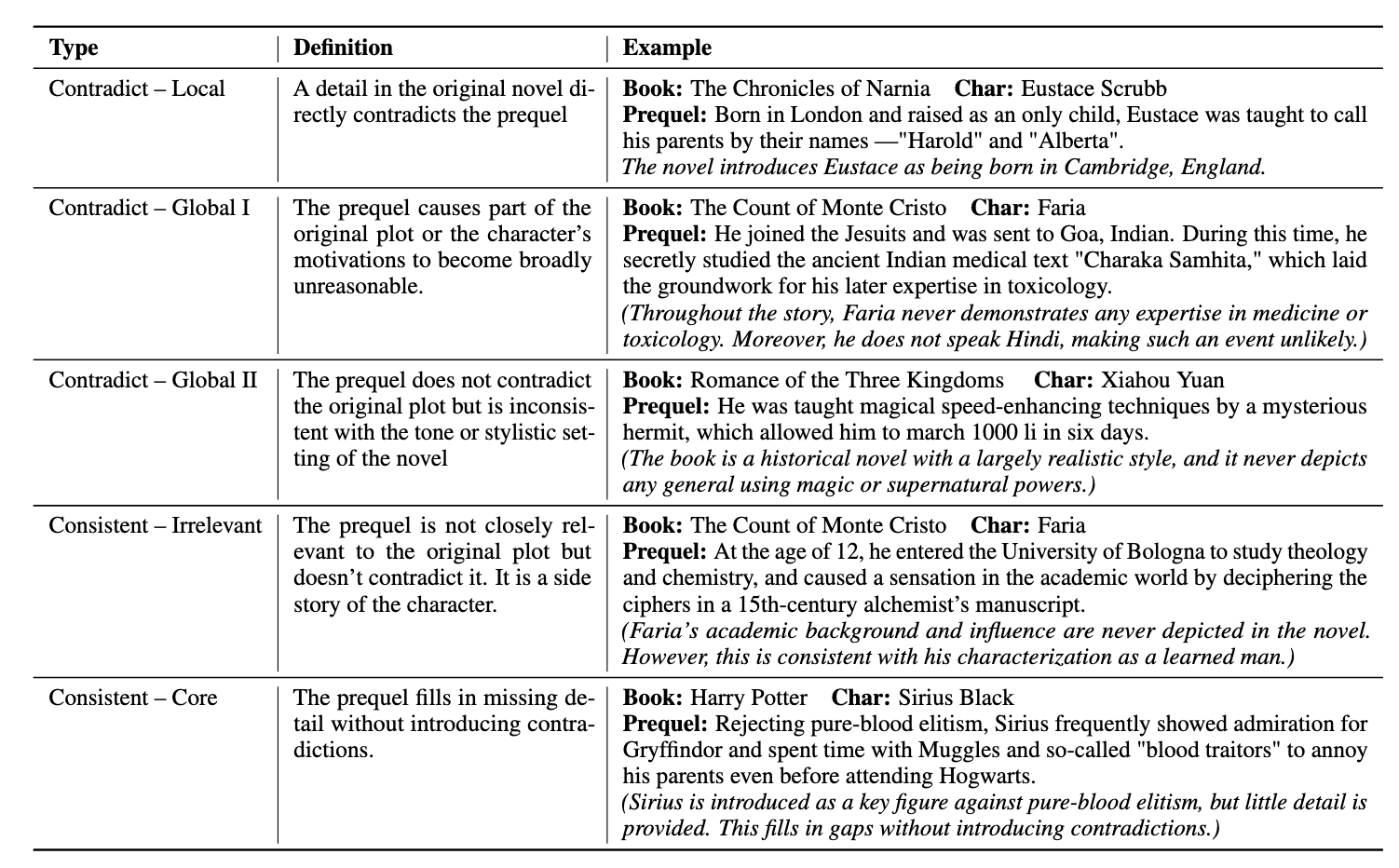
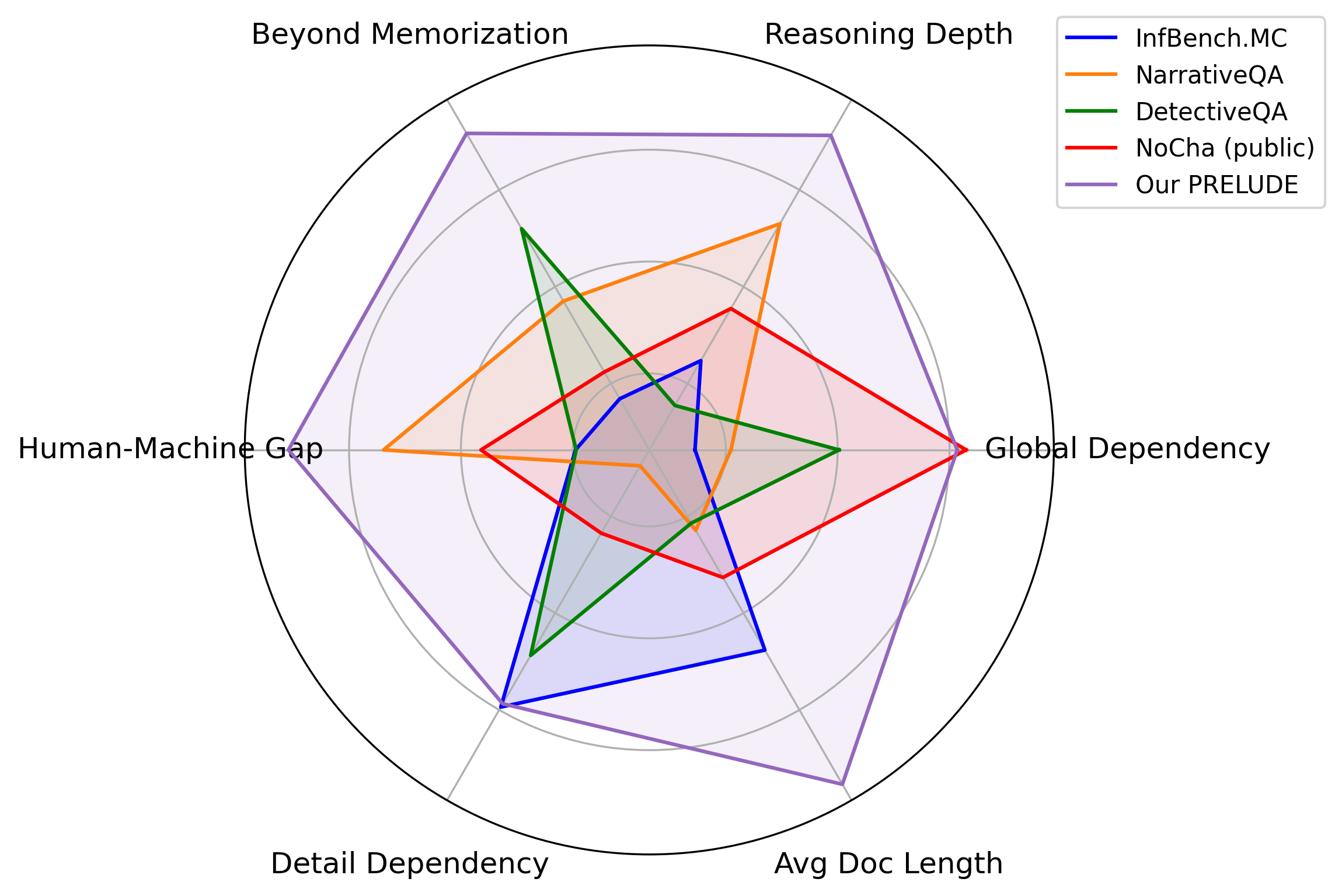
We introduce PRELUDE, a benchmark for evaluating long-context understanding through the task of determining whether a character's prequel story is consistent with the canonical narrative of the original book. Our task poses a stronger demand for global comprehension and deep reasoning than existing benchmarks -- as the prequels are not part of the original story, assessing their plausibility typically requires searching and integrating information that is only indirectly related. Empirically, 88% of instances require evidence from multiple parts of the narrative. A comprehensive study on our task demonstrates that:
- In-context learning, RAG and in-domain training with state-of-the-art LLMs, and commercial DeepResearch services, lag behind humans by >15%;
- Models often produce correct answers with flawed reasoning, leading to an over 30% gap in reasoning accuracy compared to humans;
- Recent improvements in LLMs' general reasoning capabilities do not necessarily lead to better long-context reasoning, with a notable performance drop when context is provided;
- Combined with the observation that DeepResearch performs poorly on our task, it shows that the task cannot be solved simply by retrieving existing information from the web. Instead, it requires generating new knowledge through reasoning based on learned rules.